개발자가 알아야 할 6가지 로드 밸런싱 알고리즘: 대규모 시스템의 핵심 원리
넷플릭스, 구글과 같은 대규모 시스템이 수십억 요청을 처리하는 비결은 로드 밸런싱에 있습니다. 이 글에서는 개발자가 반드시 알아야 할 6가지 로드 밸런싱 알고리즘의 역사, 현황, 그리고 최적의 선택 전략을 IT 전문 저널리스트의 시각으로 분석합니다.
목차

대규모 시스템의 숨겨진 핵심, 로드 밸런싱

넷플릭스는 매일 10억 건 이상의 API 요청을 처리합니다. 구글, 페이스북, 아마존과 같은 대규모 플랫폼 역시 수많은 사용자 요청을 안정적으로 처리합니다.
이러한 시스템이 끊김 없이 작동하는 핵심 비결은 바로 로드 밸런싱에 있습니다. 로드 밸런싱은 단순히 트래픽을 분산시키는 기술을 넘어, 시스템의 생존과 직결되는 필수 요소입니다.
과부하를 방지하고 서비스 가용성을 극대화하는 로드 밸런싱은 현대 IT 인프라의 근간을 이룹니다. 본 글에서는 개발자라면 반드시 이해해야 할 6가지 로드 밸런싱 알고리즘을 전문가의 시각에서 심층 분석합니다.
각 알고리즘의 작동 방식과 장단점을 파악하여, 여러분의 시스템에 최적화된 로드 밸런싱 전략을 수립하는 데 필요한 통찰력을 제공할 것입니다.
로드 밸런싱, 시대의 요구에 따라 진화하다

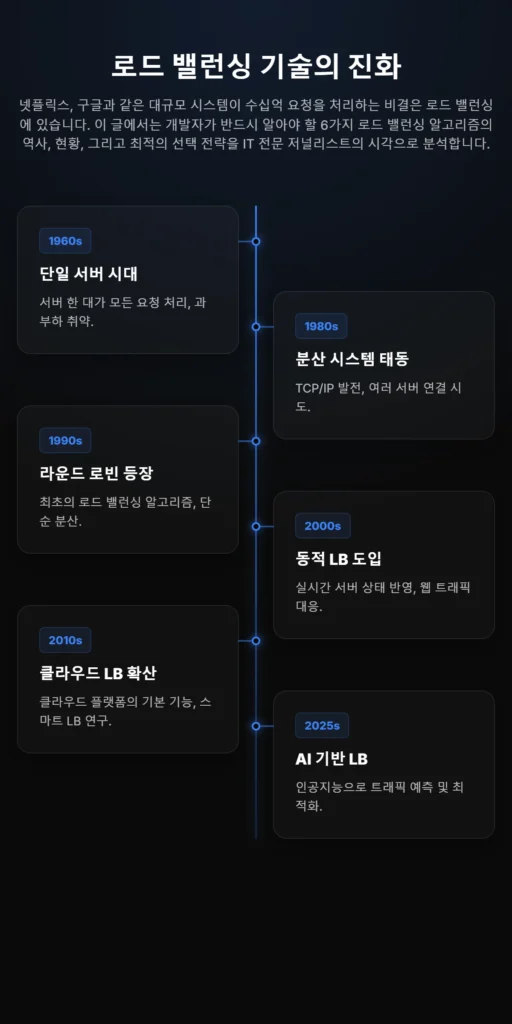
1960년대 초기 컴퓨터 네트워킹 시대에는 서버 한 대가 모든 요청을 처리했습니다. 이 시기에는 부하가 집중되면 시스템이 다운되는 문제가 빈번하게 발생했습니다.
서버 장애에 대한 대비책은 전무했습니다. 1980년대 TCP/IP 프로토콜의 발전과 함께 분산 시스템의 개념이 등장했습니다.
여러 서버를 연결하려는 시도가 시작되었고, 분산 처리의 필요성이 대두되었습니다. 서버 간 통신이 가능해지면서 부하 분산의 중요성이 인식되기 시작했습니다.
1990년대에는 로드 밸런싱 알고리즘의 초기 형태인 라운드 로빈(Round Robin)이 개발되었습니다. 이는 요청을 서버에 순서대로 분산시키는 단순한 방식이었습니다.
라운드 로빈은 이해하기 쉽고 구현이 간단하여 널리 사용되었으나, 서버 성능 차이를 고려하지 못하는 한계가 있었습니다. 2000년대에는 동적 로드 밸런싱이 도입되었습니다.
최소 연결(Least Connections)과 같은 동적 알고리즘은 서버의 실시간 상태를 감지하여 요청을 분배했습니다. 웹 트래픽이 급증하면서 고급 알고리즘의 필요성이 커진 시기였습니다.
2010년대에는 AWS, Azure와 같은 클라우드 플랫폼이 로드 밸런싱 기능을 기본으로 제공하기 시작했습니다. 기계 학습 기반의 스마트 로드 밸런싱 연구도 활발해졌습니다.
이제 로드 밸런싱은 단순한 트래픽 분산을 넘어 최적화된 시스템 운영의 핵심 기술로 자리매김했습니다.
정적 알고리즘과 동적 알고리즘의 현재

로드 밸런싱 알고리즘은 크게 정적 방식과 동적 방식으로 나뉩니다. 정적 로드 밸런싱은 미리 정해진 규칙에 따라 트래픽을 분배하며, 서버의 현재 상태와는 무관하게 작동합니다.
대표적인 정적 알고리즘으로는 라운드 로빈(Round Robin), 가중 라운드 로빈(Weighted Round Robin), IP 해시(IP Hash) 등이 있습니다. 이 방식은 구현이 간단하고 예측 가능하며 오버헤드가 적다는 장점이 있습니다.
특히 서버 성능이 유사하고 트래픽 패턴이 예측 가능한 환경, 또는 무상태(stateless) 애플리케이션에 적합합니다. 반면 동적 로드 밸런싱은 서버 풀의 실시간 성능 지표를 모니터링하여 트래픽을 지능적으로 분배합니다.
최소 연결(Least Connection), 가중 최소 연결(Weighted Least Connection), 최소 응답 시간(Least Response Time) 등이 동적 알고리즘에 해당합니다. 동적 방식은 서버 부하에 유연하게 대처하여 시스템 안정성과 효율성을 극대화할 수 있습니다.
서버 성능이 다르거나 트래픽 변동이 심한 동적 환경에 특히 유리합니다. 그러나 동적 로드 밸런싱은 실시간 모니터링이 필요하므로 구현이 복잡하고 로드 밸런서 자체의 자원을 더 많이 사용한다는 단점이 있습니다.
알고리즘 선택은 서비스 특성과 서버 환경에 따라 최적화되어야 합니다. 예를 들어, 세션 지속성이 중요한 경우 IP 해시가 유용하며, 서버별 처리 능력 차이가 클 때는 가중치를 적용한 알고리즘이 효과적입니다.

복잡성이 항상 최선은 아니다: 로드 밸런싱의 역설

로드 밸런싱 알고리즘은 더 복잡할수록 항상 더 나은 성능을 보장할까요? 표면적으로는 실시간 서버 상태를 반영하는 동적 알고리즘이 더 지능적으로 보입니다.
그러나 현실에서는 복잡한 알고리즘이 더 많은 오버헤드와 잠재적 실패 지점을 발생시킬 수 있습니다. 예를 들어, 최소 응답 시간(Least Response Time) 알고리즘은 서버의 응답 시간을 지속적으로 측정해야 합니다.
이러한 측정 과정에서 오류가 발생하거나 모니터링 시스템 자체에 부하가 걸리면 전체 시스템의 안정성에 악영향을 미칠 수 있습니다. 동적 알고리즘은 모니터링 시스템의 정확성과 신뢰성에 크게 의존하기 때문입니다.
따라서 가장 좋은 로드 밸런싱 알고리즘은 존재하지 않습니다. 애플리케이션의 특성, 트래픽 패턴, 그리고 운영 환경을 종합적으로 고려하여 최적의 알고리즘을 선택해야 합니다.
로드 밸런서 자체가 단일 장애 지점(Single Point of Failure)이 될 수 있다는 사실을 항상 인지하고, 이에 대한 이중화 및 고가용성(High Availability) 전략을 함께 고려해야 합니다.

최적의 로드 밸런싱 전략 수립 가이드

로드 밸런싱의 진정한 핵심은 특정 알고리즘 자체가 아닙니다. 실시간 모니터링과 피드백을 통한 지속적인 시스템 조정 능력입니다. 어떤 알고리즘을 선택하든, 시스템 상태를 정확히 파악하고 필요에 따라 유연하게 대응할 수 있어야 합니다.
2025년 하반기에는 인공지능(AI) 기반 로드 밸런싱이 더욱 널리 활용될 것으로 전망됩니다. AI는 예측 분석을 통해 트래픽 패턴을 학습하고, 서버 부하를 사전에 예측하여 최적의 분배 결정을 내릴 수 있습니다.
핵심 포인트 요약:
- 알고리즘 선택의 유연성: 단일 최적 알고리즘은 없으며, 서비스 특성과 트래픽 패턴에 따라 적합한 알고리즘을 선택해야 합니다.
- 모니터링의 중요성: 실시간 서버 상태 모니터링은 로드 밸런싱의 효율성과 안정성을 보장하는 필수 요소입니다.
- AI 기반 로드 밸런싱의 부상: 2025년 이후 AI는 트래픽 예측 및 최적화에 중요한 역할을 할 것입니다.
구체적 행동 지침:
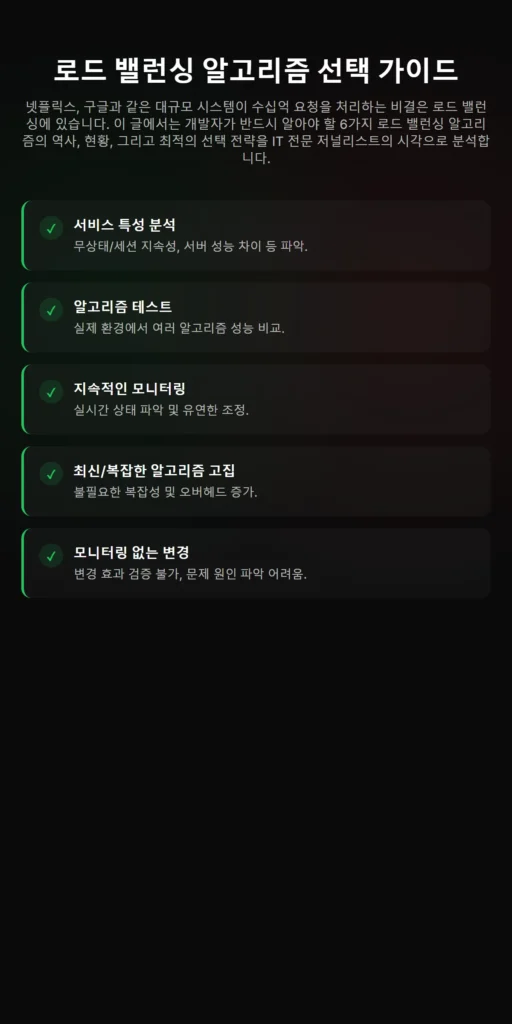
- 1단계: 서비스 특성 분석: 애플리케이션이 무상태인지, 세션 지속성이 필요한지, 서버 성능 차이가 큰지 등을 파악합니다.
- 2단계: 알고리즘 테스트 및 평가: 여러 로드 밸런싱 알고리즘을 실제 환경 또는 유사 환경에서 테스트하여 성능 지표를 비교합니다.
- 3단계: 지속적인 모니터링 및 조정: 로드 밸런서와 서버의 상태를 실시간으로 모니터링하고, 트래픽 변화에 따라 알고리즘 또는 설정을 조정합니다.
흔히 하는 실수:
- 단순히 최신/복잡한 알고리즘만 고집하는 것: 서비스에 불필요한 복잡성을 추가하고 오버헤드를 증가시킬 수 있습니다.
- 모니터링 없이 알고리즘만 변경하는 것: 변경의 효과를 검증할 수 없으며, 문제 발생 시 원인 파악이 어렵습니다.
한 줄 정리: 로드 밸런싱은 단순한 기술이 아닌, 시스템의 안정성과 성능을 결정하는 전략적 선택입니다.
이 글의 저작권은 modoomo에 귀속됩니다.