아파치 카프카: 1조 건 데이터 처리의 핵심, 그 복잡성을 해부하다
넷플릭스에서 1조 건 이상의 메시지를 처리하는 아파치 카프카의 핵심 원리와 실전 활용법을 IT 전문 저널리스트의 시각으로 분석합니다. 카프카의 역사, 메시지 구조, 파티셔닝 전략, 그리고 관리 난이도까지, 복잡한 카프카를 명확하게 이해하고 효율적으로 활용하기 위한 심층 가이드를 제공합니다.
목차

데이터 파이프라인의 심장, 카프카

넷플릭스는 매일 1조 건 이상의 메시지를 카프카로 처리하며 전 세계 최대 규모의 데이터 파이프라인을 운영합니다. 이처럼 카프카는 대규모 분산 시스템에서 실시간 데이터 처리를 위한 핵심 기술로 자리매김했습니다.
그러나 많은 개발자가 카프카의 복잡성 때문에 도입과 운영에 어려움을 겪습니다. 과연 카프카는 어떤 원리로 이러한 대규모 데이터를 처리하며, 그 이면에 숨겨진 관리 난이도는 무엇일까요?
지금부터 아파치 카프카의 핵심 개념부터 실전 활용까지, 그 복잡성을 냉철하게 파헤쳐 보겠습니다.
카프카, 분산 시스템의 진화

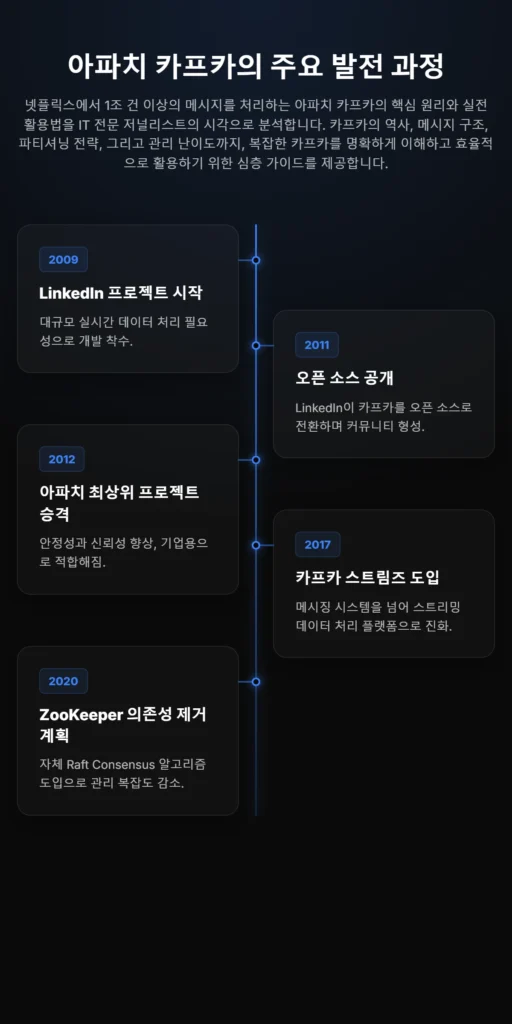
아파치 카프카는 2009년 링크드인(LinkedIn)에서 대규모 실시간 데이터 처리의 필요성을 해결하기 위해 프로젝트가 시작되었습니다. 당시 링크드인은 폭증하는 사용자 트래픽을 기존 시스템으로는 감당하기 어렵다는 한계를 인식했습니다.
이러한 배경 속에서 카프카는 분산 이벤트 저장소로 설계되었으며, 수평 확장이 가능한 아키텍처를 갖추게 되었습니다. 2011년에는 오픈 소스로 공개되며 전 세계 개발자 커뮤니티의 참여를 이끌어냈고, 2012년에는 아파치 소프트웨어 재단의 최상위 프로젝트로 승격되며 안정성과 신뢰성을 인정받았습니다.
이후 카프카는 단순한 메시징 시스템을 넘어 스트리밍 데이터 처리 플랫폼으로 발전했습니다. 2017년에는 카프카 스트림즈(Kafka Streams)가 등장하여 데이터 처리 로직을 쉽게 구현할 수 있도록 지원했습니다.
또한, 2020년에는 외부 의존성인 주키퍼(ZooKeeper)를 대체하기 위한 자체 Raft Consensus 알고리즘 도입 계획이 발표되었습니다. 이는 관리 복잡도를 낮추고 시스템의 독립적인 확장성을 높이는 방향으로 카프카가 진화하고 있음을 보여줍니다.
카프카의 핵심: 메시지 구조와 파티셔닝

카프카는 데이터를 효율적으로 처리하기 위해 독자적인 메시지 구조와 파티셔닝(Partitioning) 방식을 채택합니다. 카프카의 메시지는 헤더, 키, 값의 세 부분으로 구성됩니다.
헤더는 메시지의 메타데이터를 포함하여 로그 추적을 용이하게 합니다. 이는 마이크로서비스 간 통신에서 데이터 흐름을 파악하고 디버깅하는 데 유리합니다. 키는 메시지 라우팅에 사용되며, 동일한 키를 가진 메시지는 항상 동일한 파티션에 저장되어 메시지 순서를 보장합니다.
반면, 일반적인 메시지 큐는 단순 페이로드(Payload) 중심의 구조를 가집니다. 이 방식은 키 기반 분산 처리가 어렵고, 메타데이터 추가가 복잡하여 메시지 추적 및 디버깅에 한계가 있습니다.
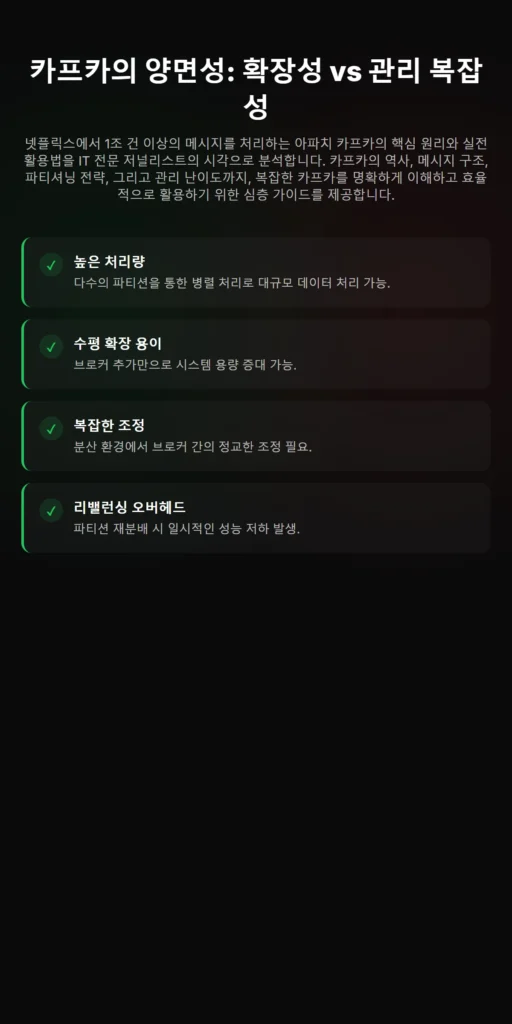
카프카의 파티셔닝 구조는 높은 처리량과 고가용성을 보장하는 핵심 요소입니다. 다수의 파티션에 메시지를 동시에 쓸 수 있어 병렬 처리 능력이 극대화됩니다. 또한, 여러 소비자 그룹이 동시에 각기 다른 파티션에서 데이터를 읽을 수 있어 시스템의 확장성과 안정성이 향상됩니다.
단일 큐 방식은 한 번에 하나의 메시지만 처리하므로 병목 현상이 발생하기 쉽습니다. 또한, 특정 서버에 장애가 발생할 경우 전체 시스템이 멈출 수 있어 장애 대응 능력이 낮습니다.
결론적으로 카프카는 분산 아키텍처와 파티셔닝을 통해 수평 확장을 가능하게 합니다. 이를 통해 기업은 증가하는 데이터 트래픽에 유연하게 대응하며, 실시간 데이터 파이프라인을 효율적으로 구축할 수 있습니다.
확장성 이면의 그림자: 카프카 관리의 복잡성

아파치 카프카는 뛰어난 확장성으로 잘 알려져 있지만, 그 이면에는 높은 관리 난이도가 존재합니다. 표면적으로는 여러 서버에서 실행되어 안정적으로 보이지만, 내부적으로는 브로커(Broker) 간의 복잡한 조정이 필수적입니다.
특히 파티션 리밸런싱(Rebalancing) 과정에서 일시적인 성능 저하가 발생할 수 있습니다. 이는 클러스터 내 브로커 수와 파티션 수 간의 조화가 매우 중요하기 때문입니다. 과도한 파티션 수는 브로커의 파일 핸들러 낭비와 관리 부담을 가중시켜 CPU 부하를 증가시키고 전반적인 성능을 저하시킬 수 있습니다.
카프카 파티션 수는 성능과 직결되며, 파티션이 늘면 병렬 처리량이 증가하는 것은 사실입니다. 그러나 파티션 수가 너무 많으면 브로커의 자원 소모가 커지고 리밸런싱 오버헤드가 발생하여 오히려 역효과를 낳을 수 있습니다.
적정 파티션 수는 프로듀서(Producer)와 컨슈머(Consumer)의 처리량 균형, 컨슈머 수, 메시지 키 사용 여부, 그리고 브로커의 CPU, 메모리, 디스크 I/O 등 자원을 종합적으로 고려하여 결정해야 합니다. 메시지 키를 사용할 경우 특정 키의 메시지가 한 파티션에 집중되지 않도록 데이터 분배 패턴을 신중하게 설계해야 합니다.
따라서 카프카의 강력한 확장성은 신중한 설계와 운영을 통해서만 온전히 발휘될 수 있습니다. 적절한 파티션 수와 브로커 구성은 시스템의 성능과 안정성을 결정하는 핵심 요소입니다.
카프카, 성공적인 도입을 위한 전략

아파치 카프카는 단순한 메시지 큐가 아닌, 실시간 스트리밍 데이터 처리 플랫폼입니다. 이 강력한 도구를 성공적으로 활용하기 위해서는 단순한 설정이 아닌 전략적인 설계와 운영이 필수적입니다.
핵심 포인트 1: 분산 아키텍처의 이해. 카프카는 분산 환경에서 높은 처리량과 확장성을 제공합니다. 이는 메시지 구조와 파티셔닝 덕분이며, 이 원리를 이해하는 것이 첫걸음입니다.
핵심 포인트 2: 파티션 수의 최적화. 과도한 파티션 수는 오히려 성능 저하와 관리 복잡성을 야기합니다. 시스템의 요구사항과 자원 상황을 고려한 신중한 파티션 설계가 중요합니다.
핵심 포인트 3: 지속적인 모니터링과 튜닝. 카프카 클러스터는 동적으로 변화합니다. 지속적인 모니터링을 통해 병목 지점을 파악하고, 필요에 따라 설정을 튜닝하는 것이 안정적인 운영의 핵심입니다.
성공적인 카프카 도입을 위한 3단계 행동 지침:
1단계: 초기 설계 단계에서 파티션 전략 수립. 데이터의 특성, 예상되는 프로듀서/컨슈머 처리량, 메시지 키 사용 여부를 고려하여 파티션 수를 결정하십시오.
2단계: 소규모 클러스터로 시작하여 점진적 확장. 처음부터 대규모 클러스터를 구축하기보다, 작은 규모로 시작하여 실제 부하를 테스트하며 점진적으로 확장하는 것이 위험을 줄이는 방법입니다.
3단계: 모니터링 시스템 구축 및 알림 설정. 카프카 클러스터의 주요 지표(처리량, 지연 시간, 리밸런싱 이벤트 등)를 실시간으로 모니터링하고, 이상 징후 발생 시 즉시 알림을 받을 수 있도록 시스템을 구축하십시오.
흔히 하는 실수와 올바른 접근:
실수: 무조건 많은 파티션을 생성하면 성능이 좋아질 것이라고 생각하는 것.
올바른 접근: 파티션 증가는 병렬 처리량을 높이지만, 브로커 자원 소모와 관리 오버헤드를 증가시킵니다. 컨슈머 수와 브로커 자원을 고려한 최적의 파티션 수를 찾아야 합니다.
한 줄 정리: 아파치 카프카는 강력한 도구이지만, 그 잠재력을 온전히 발휘하려면 깊이 있는 이해와 전략적인 접근이 필수적입니다.
이 글의 저작권은 modoomo에 귀속됩니다.